
前回の記事では、16GBのMacにローカルLLMを詰め込んでClaude Codeを動かそうとして、壁にぶつかりました。qwen3-coder:30bを走らせたところ、生成速度は0.20 tok/s。文字が1秒に1個も出てこない。30Bクラスのモデルを自前GPUで快適に動かすには、結局24GB以上のVRAMが必要という、身も蓋もない結論でした。
では、自分のマシンでは動かない大型のOSSモデルを、誰かのGPUを借りて動かせたらどうか。今回はその答えのひとつ、GLM-5.2をOllama Cloud経由でClaude Codeのバックエンドに使う話です。756Bという桁違いのモデルが、自前GPUゼロで動きました。ただし、たどり着くまでに「無料枠では403で弾かれる」という落とし穴があったので、そこも含めて実機検証した全工程を残しておきます。
※本記事は2026年6月時点の実測です。Ollama Cloudのモデルラインナップと料金は更新が速いため、実行前に公式の料金ページとモデルページを再確認してください。
この記事で分かること
- GLM-5.2がOllama Cloudの無料枠では動かない理由(403エラーの正体)
ollama launch claude --model glm-5.2:cloudでClaude Codeに繋ぐ具体的手順- 実測した生成速度(56 tok/s)と、無料枠モデルとの比較
- 「自前GPUを増設する」か「Pro課金する」かの判断軸
- やりがちなアンチパターン4選
自前GPUの限界を感じていて、強いOSSモデルでClaude Codeを動かしたい人に向けた、続編の実測ガイドです。
【最重要】GLM-5.2はOllama Cloudの「無料枠」では動かない
最初にいちばん大事なことを書きます。ここで多くの人がつまずきます。
GLM-5.2は、ollama showでモデル情報を確認できます。
ollama show glm-5.2:cloud
# architecture: glm5.2 / parameters: 756B / context length: 1000000
# capabilities: thinking, completion, tools
メタデータがちゃんと返ってくるので「お、使える」と思って実行すると、こうなります。
ollama run glm-5.2:cloud
# Error: 403 Forbidden: this model requires a subscription,
# upgrade for access: https://ollama.com/upgrade
ollama showが通ること=使えること、ではありません。 GLM-5.2はOllama Cloudの有料モデルで、無料枠(Free)では推論を実行できません。同じアカウントでも、無料枠で動くクラウドモデル(後述のnemotronなど)とGLM-5.2は枠が違うのです。
実際に、私のアカウントではnemotron-3-ultra:cloudは無料枠で普通に応答しましたが、GLM-5.2だけが403で弾かれました。動かすにはPro($20/月)以上の契約が必要です。
なぜ「ローカル」ではなく「クラウドホストOSS」なのか
ここで前作の話に戻ります。ローカルLLMの魅力は「自分のマシンで完結する=データが外に出ない・無料で回し続けられる」ことです。私もそれを追ってきました。
ただ現実には、コーディング用途で使い物になる大型モデル(30B〜)は、コンシューマ機のVRAMに収まりきりません。前作の実測では16GB機で30Bは0.20 tok/s、つまり「動くけど使えない」状態でした。
GLM-5.2は756Bです。ローカルで動かす土俵にすら乗りません。そこでOllama Cloudが提供するのが「OSSモデルの重みは公開(MIT)だが、推論はOllamaのクラウドGPU(@ollamaの告知ではUS・NVIDIA Blackwell)で回す」という選択肢です。自前GPU不要で大型OSSモデルを使える代わりに、推論コストを課金で払う。ローカルの「無料・自己完結」とは別の現実解です。
GLM-5.2とは何者か
ollama showで取れた実データと公式情報を整理します。
- パラメータ: 約756B(MoEクラスのフロンティアOSSモデル)
- コンテキスト長: 1,000,000トークン(実用的な1Mコンテキスト、プロジェクト全体を投入しやすい)
- 能力: thinking(推論)/ completion / tools(ツール呼び出し対応=エージェント用途に必要)
- ライセンス: MIT(重みが公開され、技術的にはどこでも動かせる)
- 性能ポジション: 公式説明では、同程度のトークン消費でClaude Opus 4.7〜4.8の間あたりのagentic codingを発揮するとされています(※提供元公称。本記事では速度のみ実測)
toolsに対応している点が重要です。これがあるからこそ、Claude Codeのようなエージェントツールのバックエンドとして機能します。
セットアップ:Pro契約とサインイン確認
手順はシンプルです。
- https://ollama.com/upgrade でPro($20/月)を契約する
- CLIでサインイン済みのアカウントと同一であることを確認する
- トークンを念のため更新する
ollama signout && ollama signin契約後、先ほど403だったollama run glm-5.2:cloudが通るようになれば準備完了です。
Claude Codeへの接続
接続方法は2つあります。公式の正準手順と、手動配線です。全体像はこの一枚で掴めます。
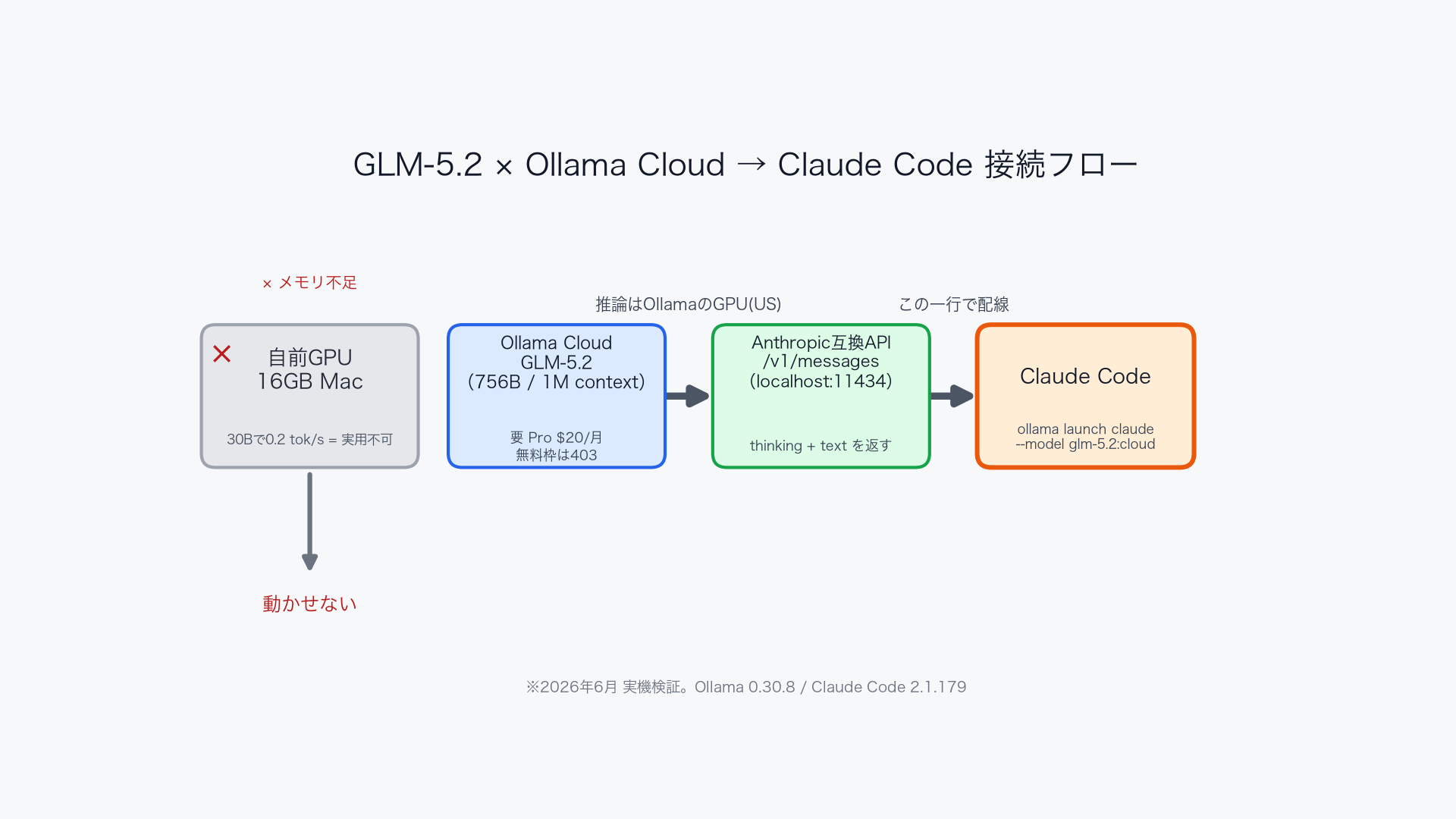
GLM-5.2 → Ollama Cloud → Anthropic互換API → Claude Code の接続フロー(2026年6月 実機検証)
方法1: ollama launch(推奨)
Ollamaには各種エージェントツールへ直接繋ぐlaunchコマンドがあります。
ollama launch claude --model glm-5.2:cloudこれでClaude CodeがGLM-5.2をバックエンドにして起動します。前作で紹介したollama launch claudeの、モデル指定をクラウドモデルに差し替えただけです。
方法2: 環境変数で手動配線
仕組みを理解したい人向けに、手動でも繋げます。OllamaはAnthropic互換のエンドポイント(/v1/messages)を提供していて、Claude Codeはここを向くだけで動きます。
export ANTHROPIC_BASE_URL=http://localhost:11434
export ANTHROPIC_AUTH_TOKEN=ollama
export ANTHROPIC_MODEL=glm-5.2:cloud
claude実際にclaude -pでワンショット実行したところ、リターンコード0で正常終了し、応答も「自分はglm-5.2:cloudで動いている」と返ってきました。Claude Code → Ollama → GLM-5.2 のフルチェーンが成立しています。
念のためエンドポイント単体でも叩いて確認しました。
curl http://localhost:11434/v1/messages \
-H "content-type: application/json" \
-d '{"model":"glm-5.2:cloud","max_tokens":256,
"messages":[{"role":"user","content":"hello"}]}'レスポンスはAnthropic形式(content配列にthinkingブロックとtextブロック、usageにトークン数)で返ってきました。Claude Codeが期待する形式そのものです。
実測:生成速度ベンチ
同じコーディングタスク(argparseでCSVの統計を出すCLIツール、例外処理込み)を投げて、Ollama APIのtotal_durationから実効速度を出しました。比較対象は無料枠で動くnemotron-3-ultra:cloudです。
- GLM-5.2:cloud(Pro): 出力3,925トークン / 69.9秒 / 約56 tok/s
- nemotron-3-ultra:cloud(無料枠): 出力1,605トークン / 52.7秒 / 約30 tok/s
GLM-5.2は無料枠モデルの約1.8倍速く、生成内容もより網羅的でした。前作の「16GBローカル30B=0.20 tok/s」と比べれば、体感は別世界です。
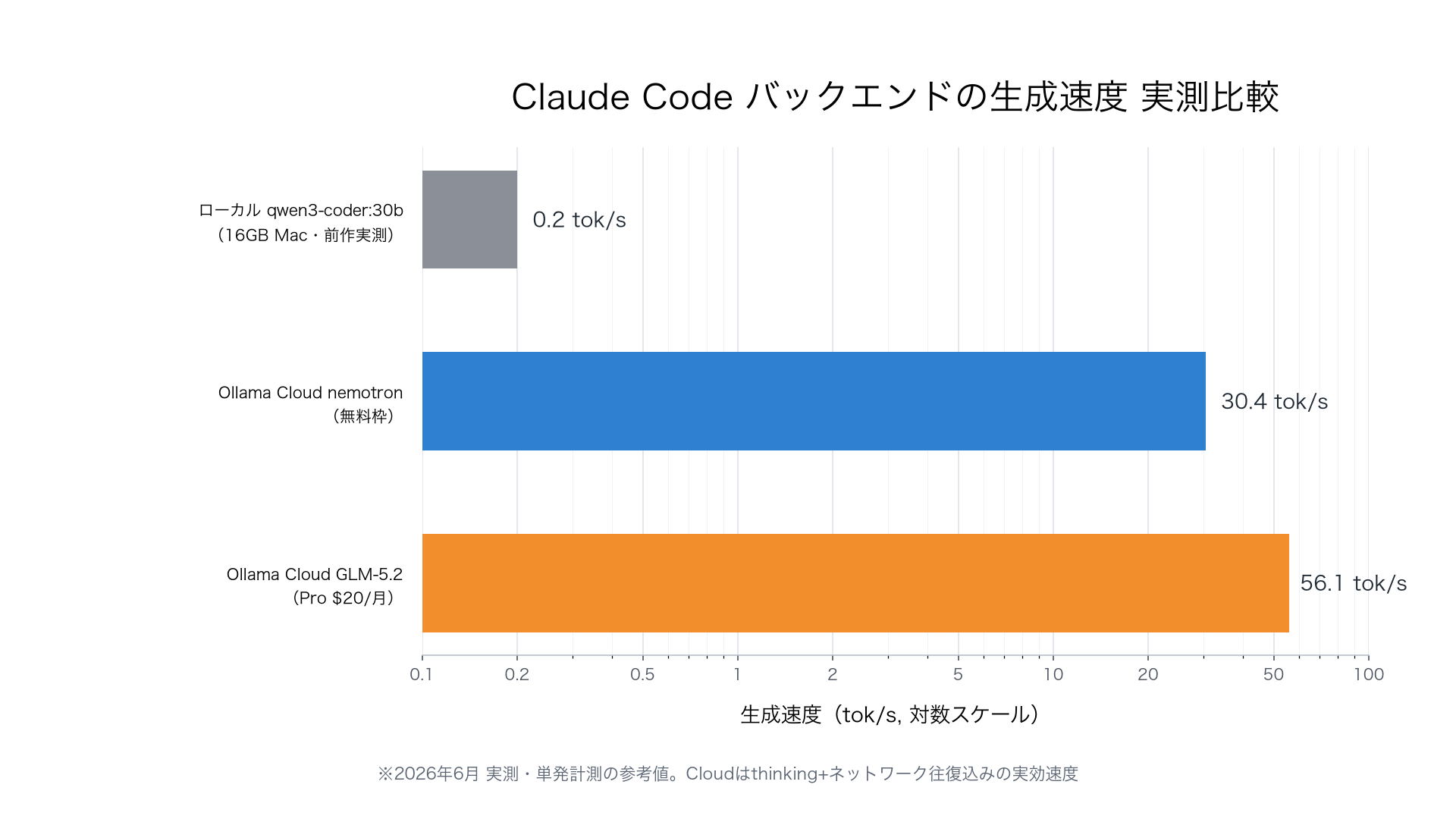
生成速度の実測比較(対数スケール)。ローカル30Bの0.2 tok/sに対し、GLM-5.2は56.1 tok/s
ひとつ実装上のTIPSを。クラウドモデルはトークン単位の詳細タイミング(eval_durationなど)をAPIで返しません。 返ってくるのはtotal_durationだけです。だから実効速度は「出力トークン÷総時間」で概算するしかなく、しかもこの値はthinkingトークンとネットワーク往復を含んだエンドツーエンドの数字です。ローカルモデルのベンチとは計測の前提が違う点に注意してください。
料金の判断軸:Free / Pro / Max
Ollama Cloudの料金は3段階です(2026年6月時点)。
- Free($0): 軽い利用向け。クラウドモデル1並列。GLM-5.2は対象外(403)
- Pro($20/月): 無料枠の約50倍のクラウド利用、3並列。GLM-5.2が使える
- Max($100/月): さらに上限が広い
判断の軸はシンプルです。「強いOSSモデルでClaude Codeを日常的に回したいが、自前GPUは足りない」なら、24GB以上のGPUを買い増す初期投資と、Pro月$20を比べることになります。月$20で756Bが56 tok/sで使えるなら、ハードを増設するより安く早い、というのが今回の実感です。一方、扱うコードが社外秘で外部に一切出せないなら、遅くてもローカル一択。ここはトレードオフです。
やりがちなアンチパターン4選
実機で踏んだ・踏みかけた罠をまとめます。
ollama showが通る=使える、と誤認する。メタデータ取得と推論実行は別物。ollama runまで確認する。- 無料枠でGLM-5.2を期待する。403で止まります。無料で試したいなら、まずnemotronなど無料枠対応モデルで感触を掴む。
- per-tokenの速度をローカル基準で語る。クラウドは
total_durationしか返さないので、ローカルのtok/sと単純比較しない。 - 「クラウド=データが自由に使われる」と決めつける/逆に無条件で安心する。データ保持ポリシーは契約時点の公式記載を必ず自分で確認する(ゼロデータ保持を掲げていても、規約は更新されうる)。
ollama launch の広がり
最後に視野を広げると、ollama launchが繋げる先はClaude Codeだけではありません。実行環境で確認できた統合先は14以上ありました。
claude / codex / codex-app / copilot / opencode / cline /
qwen / droid / kimi / vscode / hermes / pi / pool / omp ...
つまりOllamaは「ローカルやクラウドのOSSモデルを、各種エージェントツールのバックエンドに差し込むランチャー」として育っています。GLM-5.2はその目玉モデルの一例にすぎず、同じ要領でCodexやClineにも繋げます。今回のClaude Code接続は、その入り口です。
実践チェックリスト
- [ ]
ollama --versionでCloud対応版(本記事は0.30.8で検証)か確認 - [ ]
ollama show glm-5.2:cloudでモデル情報を確認 - [ ]
ollama run glm-5.2:cloudが403ならPro契約 - [ ] 契約後
ollama signout && ollama signinでトークン更新 - [ ]
ollama launch claude --model glm-5.2:cloudで接続 - [ ] 速度・データ保持ポリシーを自分の用途で確認
まとめ
- GLM-5.2(756B / 1Mコンテキスト)は、自前GPUなしでOllama Cloud経由でClaude Codeのバックエンドにできる
- ただし無料枠では403で動かず、Pro($20/月)以上が必須。
ollama showが通っても安心しない - 実測で約56 tok/s、無料枠モデルの約1.8倍。前作のローカル30B(0.20 tok/s)とは別世界
- 接続は
ollama launch claude --model glm-5.2:cloudの一行。手動ならAnthropic互換エンドポイントに向けるだけ - 「自前GPU増設 vs 月$20課金」の天秤で、用途が外部に出せるなら課金が現実解になりやすい
ローカルで完結する自由は、やはり捨てがたい。ただ、自分のマシンが追いつかない領域では、クラウドホスト型のOSSモデルという中間解が現実的な選択肢になってくる。前作で行き止まりだった「大型モデル×Claude Code」が月$20で動き出したのは、正直、ちょっと痛快でした。
コメント