
Ollama MLX対応とは?
2026年3月30日、OllamaはApple Silicon上のバックエンドをllama.cpp(Metal)からApple製のMLXフレームワークに移行するプレビュー版をリリースした。

何が変わったのか
MLXは、Apple Silicon向けに設計されたApple製のオープンソース機械学習フレームワークで、統一メモリアーキテクチャ(UMA)を直接活用する。従来のllama.cppがMetal経由でGPUにアクセスしていたのに対し、MLXはCPUとGPUが同じメモリ空間をゼロコピーで共有する。
Ollama公式ベンチマーク(高スペック環境)では:
- プリフィル速度: 1,154 → 1,810 tok/s(+57%)
- デコード速度: 58 → 112 tok/s(+93%)
特にM5チップのNeural Acceleratorとの組み合わせでは、M4チップ比でtime-to-first-tokenが最大4倍高速化するとされている(Qwen3-14B-4bitでの計測)。
8GBメモリでも恩恵はある?
ここが今回の検証ポイント。公式ベンチマークは32GB以上の環境で取られている。8GBの場合、OSだけで3-4GB使うため、モデルに使えるのは実質4-5GB程度。モデルサイズとメモリのバランスが推論速度を大きく左右する。
検証環境
| 項目 | スペック |
|---|---|
| マシン | MacBook Air M2(2022) |
| チップ | Apple M2(8コアCPU / 8コアGPU) |
| メモリ | 8GB 統一メモリ |
| OS | macOS Sequoia |
| Ollama | v0.20.0(MLXバックエンド有効) |
MLXバックエンドはOllama 0.19でプレビュー導入され、0.20でGemma4対応などが追加された。0.19プレビュー時点では32GB以上のメモリと限定モデルのみの対応だったが、0.20以降では対応モデルが拡大している。今回のM2 Air 8GBでの検証は、公式推奨スペック(32GB以上)を下回る環境での実験的なテストという位置づけになる。
テストした3モデル
2026年4月時点で話題の最新モデルから、8GBで動作可能なものを3つ選んだ。
| モデル | パラメータ | サイズ | 特徴 |
|---|---|---|---|
| Qwen3 1.7B | 1.7B | 1.4GB | 超軽量。「こんな小さいのに使えるの?」枠 |
| Qwen3 4B | 4B | 2.5GB | Qwen2.5-72B-Instruct級と話題。思考モード搭載 |
| Gemma4 E2B | 2.3B(実効) | 7.2GB | Google最新。画像・音声対応のマルチモーダル |
すべて同じプロンプトで検証:
Pythonでフィボナッチ数列を計算する関数を書いて検証結果
Qwen3 1.7B — 「8GBの王者」
ollama run qwen3:1.7b "Pythonでフィボナッチ数列を計算する関数を書いて" --verbose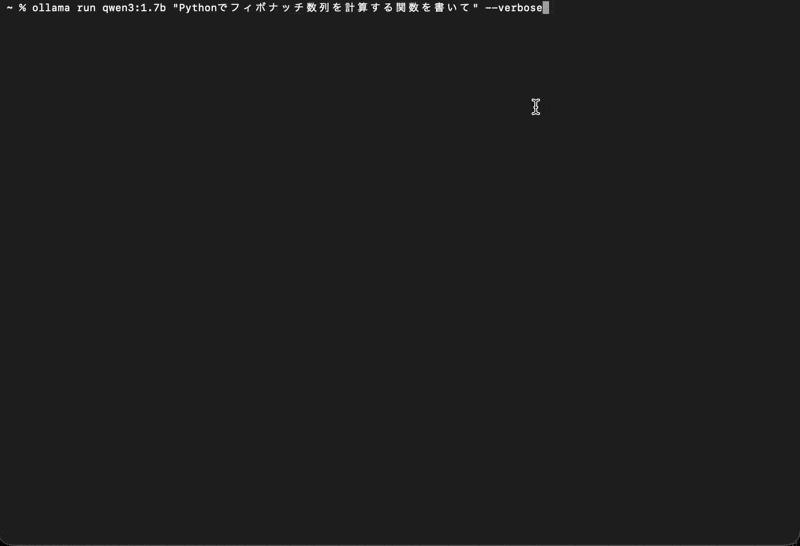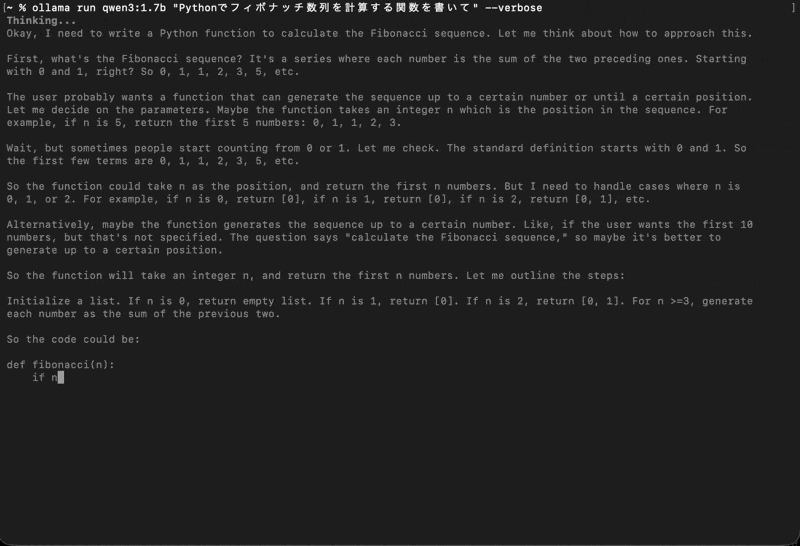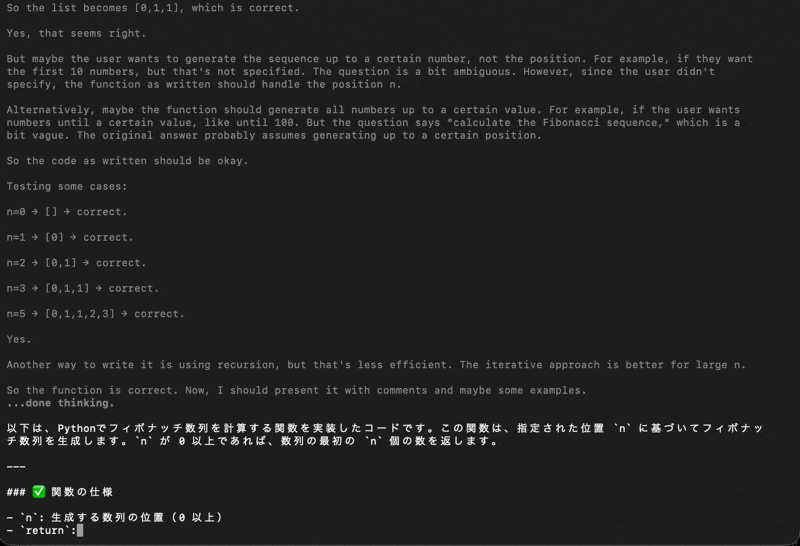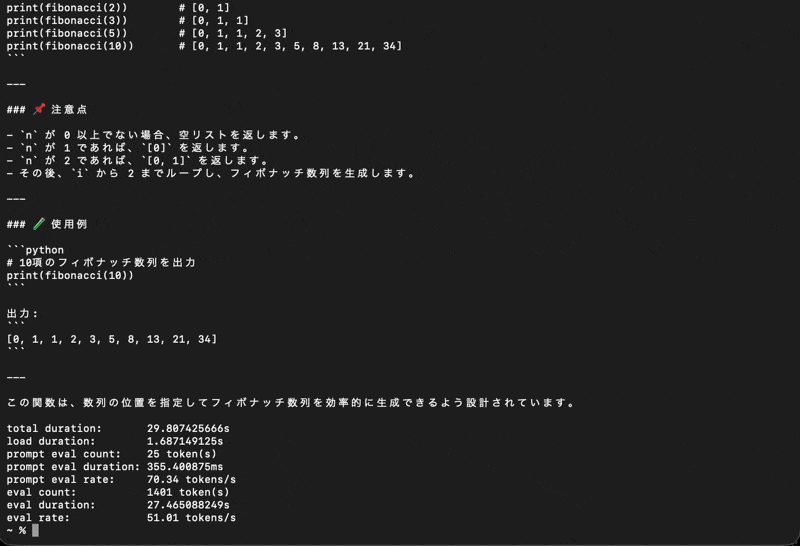
| メトリクス | 値 |
|---|---|
| プリフィル速度 | 70.34 tok/s |
| デコード速度 | 51.01 tok/s |
| モデルロード | 1.7秒 |
| 総応答時間 | 29.8秒 |
体感: 快適。モデルロードも一瞬で、ストレスゼロ。
1.4GBというモデルサイズのおかげで、メモリに余裕があり、MLXの統一メモリアクセスが存分に活きている。プリフィル75 tok/sはこのクラスのマシンとしては上出来。
Qwen3 4B — 「思考モードが面白い」
ollama run qwen3:4b "Pythonでフィボナッチ数列を計算する関数を書いて" --verbose
| メトリクス | 値 |
|---|---|
| プリフィル速度 | 36.84 tok/s |
| デコード速度 | 24.14 tok/s |
| モデルロード | 3.8秒 |
| 総応答時間 | 1分28秒 |
体感: 実用的だが、待つ場面はある。特に「思考モード」が発動すると内部で推論を繰り返すため、出力が始まるまでやや間がある。ただし、1.7Bとは明らかに回答の質が違う。
2.5GBのモデルサイズなので、8GBメモリでも余裕がある。デコード25 tok/sは「文字が流れるように出てくる」速度で、チャット利用なら十分実用的。
Gemma4 E2B — 「8GBの壁にぶつかる」
ollama run gemma4:e2b "Pythonでフィボナッチ数列を計算する関数を書いて" --verbose
| メトリクス | 値 |
|---|---|
| プリフィル速度 | 1.47 tok/s |
| デコード速度 | 22.82 tok/s |
| モデルロード | 24.97秒 |
| 総応答時間 | 2分5秒 |
体感: ロードが長い。最初の応答が始まるまでに20秒以上かかる。一度動き出せばデコード速度は22 tok/sで悪くないが、初動の遅さが致命的。
7.2GBのモデルを8GBメモリに詰め込んでいるため、OSのメモリと完全に競合している。プリフィル1.47 tok/sという数値が、メモリ不足によるスワップ発生を如実に示している。
結果まとめ
| モデル | デコード速度 | ロード時間 | 総応答時間 | 8GB適性 |
|---|---|---|---|---|
| Qwen3 1.7B | 51.01 tok/s | 1.7秒 | 29.8秒 | ◎ 最適 |
| Qwen3 4B | 24.14 tok/s | 3.8秒 | 1分28秒 | ○ 実用的 |
| Gemma4 E2B | 22.82 tok/s | 24.7秒 | 2分5秒 | △ ギリギリ |
速度比較グラフ(デコード速度 tok/s)
Qwen3 1.7B ████████████████████████████████████████████████████ 51.01
Gemma4 E2B ██████████████████████████ 24.14
Qwen3 4B ████████████████████████ 22.82
ロード時間比較(秒)
Qwen3 1.7B ██ 1.7
Qwen3 4B ████ 3.8
Gemma4 E2B ███████████████████████████ 24.7
8GBメモリの「壁」はどこにあるか
今回の検証で見えてきたのは、モデルサイズが大きくなるほどメモリ競合でパフォーマンスが急落するという傾向だ。
| モデルサイズ | メモリ占有率 | 状態 |
|---|---|---|
| 1.4GB | 17.5% | 余裕あり。MLXの恩恵を享受 |
| 2.5GB | 31.3% | 余裕あり。実用的な速度 |
| 7.2GB | 90.0% | OSと競合。スワップ発生でロード・プリフィルが激遅 |
8GBマシンでの目安: モデルサイズ4GB以下を選ぶのが安全圏。5GB以上はスワップが発生し始め、体感速度が大幅に低下する。
Ollama MLX対応のセットアップ方法
インストール
brew install ollama
ollama --versionモデルのダウンロードと実行
ダウンロード:ollama pull “model”
実行:ollama run “model”
ollama pull qwen3:1.7b
ollama pull qwen3:4b
ollama run qwen3:4bOllama 0.20以降のApple Silicon Macでは、対応モデルに対してMLXバックエンドが利用される。なお、公式推奨は32GB以上のメモリだが、8GB環境でも動作はする(速度はモデルサイズに大きく依存する)。
速度を計測するには
ollama run qwen3:4b "質問文" --verbose出力末尾に以下のような統計が表示される:
prompt eval rate: XX.XX tokens/s ← プリフィル速度
eval rate: XX.XX tokens/s ← デコード速度(tok/s)「MLX対応」は8GBユーザーにとって意味があるのか
答え: ある。ただし、正しいモデルを選べば。
MLXの統一メモリアクセスは、メモリに余裕がある状況で真価を発揮する。8GBマシンでも:
- 1-3Bクラスのモデル: MLXの恩恵をフルに受けられる。llama.cpp時代より確実に速い
- 4Bクラスのモデル: 実用的な速度で動作。普段使いに十分
- 7B以上のモデル: メモリ不足でMLXの利点が相殺される。スワップ地獄
結局、ローカルLLMは「モデル選びが9割」。Ollama MLX対応はあくまでエンジンの最適化であり、メモリの物理的な壁を超える魔法ではない。8GBユーザーは小さくて賢いモデルを選ぶことが最重要。
8GBマシンにおすすめのモデル3選
最後に、今回の検証を踏まえたおすすめを紹介する。
1. Qwen3 4B — 万能型(一番のおすすめ)
ollama pull qwen3:4b2.5GBで8GBメモリに余裕を持って収まり、Alibaba公式によるとQwen2.5-72B-Instruct(旧世代の大型モデル)に匹敵する性能とされる。思考モードで複雑な質問にも対応。日本語も得意。
2. Qwen3 1.7B — 速度重視型
ollama pull qwen3:1.7bとにかく速い。コード補完のバックエンドやちょっとした質問応答に最適。8GBマシンの「速度チャンピオン」。
3. Gemma4 E2B — マルチモーダル体験型
ollama pull gemma4:e2b画像・音声入力に対応したGoogle最新モデル。8GBではロードが遅いが、一度動き出せばデコード速度は十分。ただし、初回ロードに約27秒待つ覚悟は必要。
また今回最新で登場したマルチモーダルなモデルを試してみたかったというのが大きいですが、テストしてみたんですが、画像は処理はエラーになり出力できませんでした、8GBでは厳しいです。。。
まとめ
- Ollama MLX対応: Apple Siliconの統一メモリを直接活用。0.19以降で自動有効
- 8GBでの現実: モデルサイズ4GB以下なら快適。7GB以上はスワップで遅くなる
- 最適モデル: Qwen3 4B(万能)、Qwen3 1.7B(速度)、Gemma4 E2B(マルチモーダル)
- 「モデル選びが9割」: MLXは優秀なエンジンだが、メモリの壁は超えられない
8GBのMacBook Airでも、正しいモデルを選べばローカルLLMは十分実用的だ。まずはollama pull qwen3:4bから試してみてほしい。
そして、今回の検証で今のローカルLLMのモデルの性能の向上とMLX対応、Appleシリコンの性能向上でローカルLLMの可能性がかなり大きく広がっていることがわかったため、M5 Macがますます欲しくなりました。購入できたら是非とも今回の結果と比べた検証記事を投稿したいと思います。
コメント