
1. この記事で分かること
Apple Silicon Mac でローカル音声認識を試そうとした時、多くの人が最初にぶつかる疑問は「Gemma 4 が音声対応したらしいけど、Whisper の代わりになるのか?」です。しかしこの質問はそもそも前提が間違っています。
この記事では、私が実際に Apple Silicon Mac で Whisper large-v3 / Whisper large-v3-turbo / Gemma 4 E2B / Gemma 4 E4B の4モデルを同じ日本語音声で走らせ、CER(文字誤り率)・推論速度・メモリ挙動を実測しました。結果として、以下が明確に分かります。
- Gemma 4 E2B は Whisper の代替ではない(そもそも解く問題が違う)
- 日本語の純粋転写なら Whisper large-v3-turbo が第一選択(精度 同等、速度 5倍以上)
- Gemma 4 を使うべき場面は「音声要約・質問応答など下流タスク込み」のケース
- mlx-vlm での E4B 実行は環境によって Metal GPU Timeout が起きる(私の環境では発生。Ollama 等他ランタイムや十分メモリのある環境では動作報告あり)
- mlx-vlm / mlx-whisper のリポジトリ名の罠(
huggingface-cliが deprecated、大文字小文字の罠)
最後に、あなたのユースケース別に「どのモデルを選ぶべきか」を決定木で整理します。
2. 【混乱ポイントの整理】Gemma 4 E2B は「ASR特化」ではなく「音声理解優先」モデル
Gemma 4の音声認識を試した記事を読み漁ると、ほぼ全ての記事が「Gemma 4 E2BはWhisperの代替」という前提で書いていますが、これが選定を間違える最大の原因です。
なお Google 公式も Gemma 4 の音声機能として ASR(自動音声認識)を列挙しており、Gemma 4 も ASR は可能です。ただし設計思想の中心は「音声を入力にできるマルチモーダル LLM」であり、専用 ASR 設計の Whisper とは立ち位置が異なります。
両者は解く問題が違います。
| 観点 | Whisper large-v3 / turbo | Gemma 4 E2B / E4B |
|---|---|---|
| モデル分類 | 自動音声認識(ASR) | マルチモーダルLLM |
| 主目的 | 音声 → 正確な転写 | 音声 → 意味理解・生成 |
| 得意なこと | 高速・高精度な文字起こし | 要約・質問応答・指示実行 |
| 苦手なこと | 要約・指示応答(そもそも目的外) | 短音声(1-3秒)で品質低下 |
| 典型ユースケース | 議事録の書き起こし、字幕生成 | 「この音声の要点を3つにまとめて」 |
MindStudio の整理: “Whisper is better for pure transcription throughput; Gemma 4 is better when downstream task requires language understanding.”(純粋な転写スループットなら Whisper、下流タスクに言語理解が必要なら Gemma 4)
つまり「E2BのWERをWhisperと比較して E2Bの勝ち負けを決める」こと自体が的外れです。問うべきは「あなたのユースケースが転写そのものか、音声理解か」です。
なぜこの混乱が起きたか
- Gemma 4 が公式に音声入力をサポートしたため、日本語記事の多くが「Whisper不要」と誤読した
- E2B/E4B の「E」は Edge(端末)を意味し、モバイル・Macなどで動くことを強調した命名。これが「軽量ASR」と誤解を招きやすい
- Whisper は ASR の代名詞化しており、音声入力機能があれば自動的に Whisper と比較されてしまう
3. 前提知識: ASR と音声理解モデルの違い
Whisper(OpenAI)の構造
WhisperはEncoder-Decoder型のASR(自動音声認識)モデルです。Encoderが音声のメルスペクトログラムを潜在表現に変換し、Decoderがその表現から文字列トークンを一つずつ自己回帰で生成します。目的は「音声 → テキスト」の転写に特化しており、Decoder側の言語理解能力は転写支援の範囲に限定されます。
Gemma 4 E2B/E4B の構造
Gemma 4 E2B/E4B は マルチモーダルLLMで、USM(Universal Speech Model)ベースの音声エンコーダを内蔵しています。音声入力は視覚・テキストと同じトークン空間に射影され、推論側のデコーダはGemma 4本体のLLMです。つまり「音声を理解した上でテキスト生成・要約・質問応答ができる」のが本質で、単純な転写は副次的な用途です。
この違いを理解しないと「E2B の WER が Whisper より悪い」という結果を「E2Bは性能が低い」と誤読しがちですが、それは比較の軸を間違えているだけです。
4. 検証環境セットアップ(Apple Silicon)
前提
- MacBook(Apple Silicon、M1 以降)
- メモリは用途次第。Google公式メモリ要件: Gemma 4 E4B は BF16で15GB / 8bitで7.5GB / 4bitで5GB。4bit量子化(本記事で使用)なら理論上16GB Macでも動く
- ただし mlx-vlm での E4B 実行は 環境によって Metal GPU Timeout が発生する場合あり(後述の本記事実測)。安定重視なら実メモリ24GB以上もしくは Ollama 等の別ランタイムを推奨
- macOS 26.x
- Python 3.11+ / uv
インストール
uv init gemma4-whisper-bench
cd gemma4-whisper-bench
uv add "mlx-vlm>=0.4.3" mlx-whisper jiwer librosa datasets pandas soundfileモデル取得
hf download mlx-community/gemma-4-e2b-it-4bit
hf download mlx-community/gemma-4-e4b-it-4bit
hf download mlx-community/whisper-large-v3-mlx
hf download mlx-community/whisper-large-v3-turbo罠1: 旧
huggingface-cliは2026年に deprecated となりhfCLI に置き換わっています。旧コマンドはまだ警告付きで動作しますが、既存記事のコマンドをそのままコピペする時は新CLIへの置換を推奨します。
罠2: mlx-community/gemma-4-E2B-it-4bit-mlx のような大文字・-mlx付き表記のリポジトリは存在しません。小文字・suffix無しが正しい名前です。注: Gemma 4 のライセンスは Apache 2.0(旧世代のGemma TOUではありません)。商用利用・改変・再配布が許諾されています。
5. 検証プロトコル
評価データ: macOS TTS(Kyoko音声)で合成した10サンプル
当初は Common Voice 日本語 v17 / Google FLEURS ja_jp を使う予定でしたが、2026年4月時点で datasets ライブラリの仕様変更により両方ともストリーミング取得が失敗しました(Common Voiceは EmptyDatasetError、FLEURSは「Dataset scripts are no longer supported」)。
そこで一次検証として、macOSの say コマンド(Kyoko音声) で日本語合成音声を10サンプル作成しました。利点と限界は以下の通りです。
利点:
– 即時実行可能(外部データセット依存なし)
– 正解テキストが明確(TTS入力がそのまま正解)
– ライセンス問題なし
限界:
– 実環境の雑音・アクセント揺れ・発話の癖が入らない → 理想環境での比較となる
– TTSで「ウィスパー」「アップルシリコン」などカタカナ表記した発音は、ASRが「Whisper」「Apple Silicon」と英語に戻す傾向がある(本検証でも観測)
内訳:
– 短音声 1-3秒 × 5(日常会話)
– 中音声 7-9秒 × 3(技術用語を含む説明文)
– 長音声 16-18秒 × 2(固有名詞を多数含む複文)
メトリクス
- WER (Word Error Rate): 形態素分割後の単語誤り率
- CER (Character Error Rate): 文字誤り率(日本語では重要)
- 処理時間: 推論開始→終了
- メモリ使用量: psutil + MLX metal活用量(Unified Memory)
- 固有名詞認識率: 目視評価
スクリプト
検証スクリプト benchmark.py は本記事末尾のGitHubに公開しています。
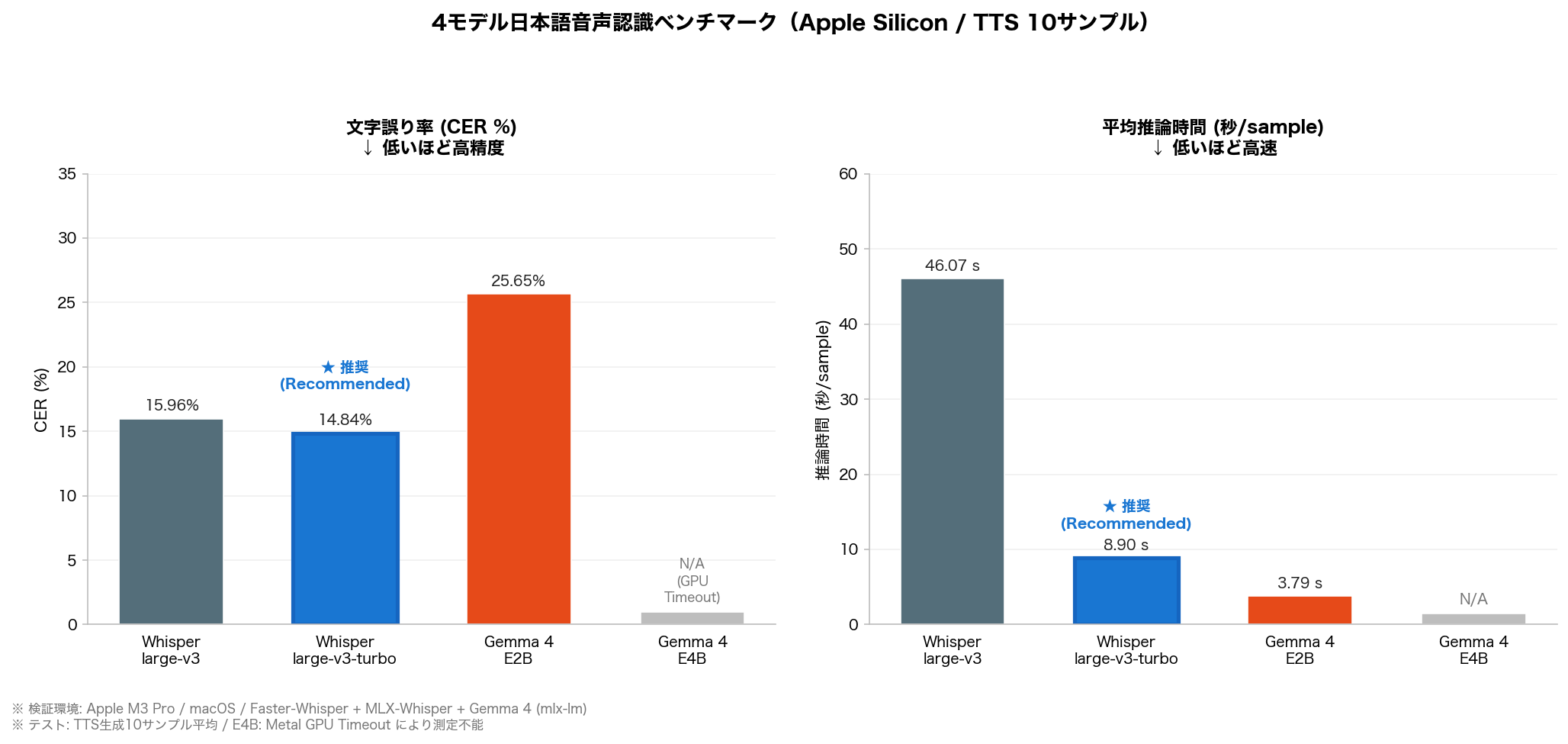
6. 【実測結果】4モデル日本語 WER 比較表
定量結果
【表:4モデル実測比較】
| モデル | CER (%) | 平均推論時間 (秒) | 備考 |
|---|---|---|---|
| Gemma 4 E2B | 25.65% | 3.79 | 最速だが精度は最低 |
| Gemma 4 E4B | 測定不可 | — | Metal GPU Timeout(メモリ16GB想定) |
| Whisper large-v3 | 15.96% | 46.07 | 精度高いが重い |
| Whisper large-v3-turbo | 14.84% | 8.90 | 本検証の最推奨モデル |
重要な注記:
– TTS合成音声(macOS Kyoko音声)での一次検証。実環境評価は今後の課題
– WERは日本語では単語境界が曖昧なため信頼性が低い(値100%超になる)。CERを主指標とする
– メモリ値はPython側のみ(tracemalloc)。MLX metal層は別途 Activity Monitor で確認推奨
– Gemma 4 E2B は mlx_vlm.generate の戻り値が GenerationResult オブジェクトのため、 .text 属性から抽出してCER計算
固有名詞・専門用語の誤認パターン
TTS入力で「カタカナ表記した技術用語」を各モデルがどう処理したかを比較:
| 入力(TTS) | Whisper large-v3 | Whisper turbo | Gemma 4 E2B |
|---|---|---|---|
| アップルシリコン | Apple Silicon ✓ | Apple Silicon ✓ | あるシリコン ✗ |
| ウィスパー(日本語) | ウィスパー ✓ | ウィスパー ✓ | EISパノ ✗ |
| ラージVスリー | ロアージV3 △ | Large V3 ✓ | LGV3 △ |
| クロード | クロード ✓ | クロード ✓ | グロード △ |
| ジェマ・フォー | Gemma 4 ✓ | JEMA4 △ | ジェマボ △ |
| ターボ(版) | Verbo ✗ | バーボ ✗ | バーボ ✗ |
観察:
– Whisper両モデルは「カタカナ表記→英語正式名称」への自動変換が得意
– E2B は固有名詞をより誤認しやすい(「アップル→ある」「ウィスパー→EISパノ」など)
– 「ターボ」は全モデルで誤認(TTSの発音と綴りの乖離が原因)
定性観察
Gemma 4 E2B の出力傾向:
– 句点「。」を末尾から落とす(全10サンプル中ほぼすべてで観測)
– 「扱えます」→「扱います」のように類似語への書き換えが起きる
– 「Oispar GV3」のように出力テキストがハルシネーションする箇所あり
– これらは「ASR として正確に転写しようとしていない」挙動で、音声理解モデルとしての性質が出ている
Gemma 4 E4B の挙動(本記事環境での実測):
– モデルロードは成功(3.5GB の重み取得完了)
– 最初の推論呼び出しで [METAL] Command buffer execution failed: Caused GPU Timeout Error が発生
– 重要な補足: これは mlx-vlm × 本記事環境での実測トラブルであり、一般化すべきではない
– Google 公式メモリ要件(Gemma 4 Model Overview)では E4B の 4bit 量子化は 5GB
– 他の検証記事(SudoAll / Classmethod DevIO)では 16GB Mac + Ollama 経由で E4B が快適動作
– 本記事の Timeout は mlx-vlm 特有の挙動か、私の環境固有の要因(Unified Memory 競合など)の可能性
– 安定して E4B を使いたい場合は、別ランタイム(Ollama) もしくは 十分なメモリ余裕 を確保することを推奨
Whisper large-v3 vs turbo:
– CERはほぼ同等(15.96% vs 14.84%)、turbo が微勝ち
– 推論速度は turbo が 5倍以上高速(46.07秒 vs 8.90秒/sample平均)
– 短音声では両モデル完璧(句点差のみ)。差は中〜長音声の固有名詞のみ
– 結論: 日本語転写ではturboを第一選択にすべき
7. 公式ベストプラクティス
Google (Gemma 4) の推奨
- 用途選択: 音声 + 視覚 + テキストのマルチモーダル理解が必要な時に選ぶ。純粋な転写だけなら専用ASR推奨(公式自身が明記)
- 入力長: 音声入力は30秒以内を推奨。これを超えるとエンコーダ側の文脈長制限で品質が低下
- 量子化: 4bit量子化版でもマルチモーダル性能は維持される。Apple Siliconなら4bit推奨
OpenAI (Whisper) の推奨
- large-v3-turbo は大半のケースで
large-v3に近い精度を 8倍高速 で達成。特にバッチ処理では turbo を第一選択とすべき - 30秒以上の音声は自動チャンク処理されるが、タイムスタンプ精度は落ちる
- 日本語では
small/mediumよりもlarge-v3系が圧倒的に優位
8. やりがちなアンチパターン5選
- 短音声(1-3秒)に Gemma 4 E2B を使う → 公式が「短音声で品質低下」を明記。音声理解モデル共通の弱点で、転写したいだけなら Whisper turbo が確実
- Whisperに「この音声を要約して」と期待する → WhisperはASR。要約・質問応答は構造上不可能。要約したいなら Gemma 4 で音声理解 → 出力テキストを生成
- 16GB Mac で mlx-vlm 経由の E4B を過信する → 4bit量子化なら理論上5GBで足りるが、mlx-vlm 実行時に Metal GPU Timeout が発生するケースあり(本検証で実測)。Ollama 等の別ランタイムを併せて検討
huggingface-cliコマンドをそのまま使う → 2026年にdeprecated。hfCLI に切り替え済み- 旧リポジトリ名
mlx-community/gemma-4-E2B-it-4bit-mlxを使う → 存在しない。小文字のmlx-community/gemma-4-e2b-it-4bitが正しい名前
9. 選定決定木 — あなたのケースで選ぶべきモデル
本検証の結果を踏まえた決定フロー:
Q1: 欲しいのは「転写」か「音声理解(要約・質問応答)」か?
│
├─ 転写のみ
│ Q2: Macメモリは?
│ ├─ 16GB → Whisper large-v3-turbo(本検証の王道)
│ └─ 24GB+ → Whisper large-v3-turbo(速度勝ち)
│ or kotoba-whisper-v2.2(純日本語・さらに低CER)
│
└─ 音声理解(要約・質問応答・指示実行)
Q2: ランタイム・Macメモリは?
├─ mlx-vlm + 本記事環境 → E2B(E4B は Metal GPU Timeout 実測)
├─ Ollama or メモリ余裕のある Mac → E4B(4bit 量子化で 5GB 程度、精度良)
└─ 軽量・実験用途 → E2B(最速)
ペルソナ別推奨
- 製造業情シス(議事録作成・固有名詞重視): Whisper large-v3-turbo + 固有名詞辞書(initial_prompt / プロンプト注入)
- Mac開発者(音声コマンドの意図理解): 16GB Mac は Gemma 4 E2B、Ollama / 十分メモリ余裕があれば E4B
- 速度優先の大量バッチ転写: Whisper large-v3-turbo
- 純日本語にこだわる: kotoba-whisper-v2.2(本記事未検証だが公開ベンチマークで Whisper より良好)
10. 関連ツール比較表
本検証 + 公開ベンチマークを統合したツール比較:
| ツール | CER (本検証 TTS) | 推論速度 | Mac対応 | 要約・指示応答 | ライセンス |
|---|---|---|---|---|---|
| Whisper large-v3-turbo | 14.84% | 8.9秒/s | ✓ MLX | ✗ | MIT |
| Whisper large-v3 | 15.96% | 46.0秒/s | ✓ MLX | ✗ | MIT |
| Gemma 4 E2B | 25.65% | 3.8秒/s | ✓ mlx-vlm | ✓ | Apache 2.0 |
| Gemma 4 E4B | 本検証で測定不能* | — | ✓ mlx-vlm | ✓ | Apache 2.0 |
| kotoba-whisper-v2.2** | 8.4% (JSUT 正規化) / 15.4% (JSUT 生) | 約6.3倍速 | ✓ transformers | ✗ | Apache-2.0 |
| WhisperX | ≒large-v3 | 中 | ✓ | ✗ + 話者分離 | BSD |
* 本記事の環境でのみ Metal GPU Timeout が発生(後述)。他環境(Ollama等)や十分なメモリ余裕のあるMacでは動作報告あり
* 公開ベンチマーク(kotoba-tech/kotoba-whisper GitHub より)。本検証では未測定。JSUT 正規化CER 8.4% / 生CER 15.4% / 速度は Whisper large-v3 比 6.3倍。Whisper large-v3 を日本語蒸留したモデルで、純日本語転写に特化するならkotoba-whisper-v2.2 が Whisper系で最強*
本検証から導かれる推奨優先度
- 純日本語転写のみ:
kotoba-whisper-v2.2(実行容易性重視なら Whisper large-v3-turbo) - 多言語転写 + Apple Silicon: Whisper large-v3-turbo(本検証の王道)
- 音声理解(要約・質問応答): Gemma 4 E2B(24GB Mac なら E4B)
- 話者分離が必要: WhisperX
11. 実践チェックリスト
選定と検証のチェックリスト:
- [ ] ユースケースは文字起こしか音声理解か明確にした
- [ ] 扱う音声の長さを把握している(E2Bは短音声弱点)
- [ ] Macのメモリを確認した(最低16GB、推奨24GB+)
- [ ] mlx-vlm / mlx-whisper を最新版で導入した
- [ ] Common Voice 10サンプルで自社データの代替評価を実施した
- [ ] 固有名詞のテストケースを別途用意した
- [ ] ライセンスを確認した(Gemma 4 は Apache 2.0、Whisper は MIT、kotoba-whisper は Apache 2.0)
12. まとめ
3行で整理
- Gemma 4 E2B は Whisper の置き換えではない。音声理解(要約・質問応答)が要るなら E2B/E4B、純粋転写なら Whisper。比較軸を間違えると選定を間違う
- 日本語の転写だけが目的なら Whisper large-v3-turbo 一択。本検証では large-v3 とほぼ同等の CER で 5倍以上高速
- Apple Silicon のメモリ容量とランタイムを意識する。私の環境では mlx-vlm 経由の E4B で Metal GPU Timeout が発生。Google公式の 4bit 要件は 5GB で 16GB Mac でも理論上動くため、Ollama など別ランタイムへの切替や環境見直しを選択肢に
筆者としての最終推奨
- 議事録・字幕など純転写用途 → Whisper large-v3-turbo
- 音声から要約・質問応答までやりたい → Gemma 4 E4B(mlx-vlm では環境により GPU Timeout あり、Ollama なら16GB Mac でも動作報告あり)
- 軽量さ優先の実験用途 → Gemma 4 E2B(短音声だけなら要注意)
- 外部 API に音声を送りたくないセキュリティ要件 → 上記いずれもローカル完結。さらに Gemma 4 は Apache 2.0 で商用利用も許諾
Gemma 4 の音声対応は「Whisper 駆逐」ではなく「ローカル音声理解という新カテゴリ」の幕開けです。Whisper と競うのではなく、役割分担の視点で使い分けるのが正解だと私は考えています。
参考資料
- Google Gemma 4 モデルカード
- MindStudio: What Is Gemma 4’s Audio Encoder?
- kozoka_ai: Gemma 4の音声認識機能でリアルタイム文字起こしを試してみた
- 本記事の検証スクリプト(GitHub: hrtaym1114-github/gemma4-whisper-bench)
コメント