
「Claude Codeは便利だが、月額の費用と、コードを外部に送ることへの不安が消えない」。この記事は、その2つを同時に解決するローカルLLMでのClaude Code運用を、ツール選びの段階から整理するためのガイドです。
結論から言うと、選択肢は乱立していますが、Macユーザーがまず選ぶべきは Ollama です。しかも2026年は接続が劇的に簡単になりました。かつては環境変数を手で設定する必要がありましたが、いまは ollama launch claude という1コマンドでClaude Codeをローカルモデルに繋いで起動できます(Ollama v0.15以降)。本記事では、4ツールをハードウェア別の判断軸で整理し、この最新のワンコマンド接続まで実機で解説します。
この記事を読むと、次のことが分かります。
- 自分の環境(Mac / AMD / Windows)で、どのローカルLLMツールを選べばいいか
- Claude Codeをローカルモデルに繋ぐ具体的な手順
- 「API費用ゼロ」「コードを外部送信しない」が本当に成立するのか
対象読者は、Apple Silicon MacでローカルLLMを試したい開発者、そして社内規定でクラウドAIを使えない法人・社内DX担当の方です。

図: ローカルでClaude Codeを動かす4ツールの要点(M5/16GB実測値つき)
この記事で分かること
この記事のゴールは、「自分のMacでClaude Codeをローカル運用するなら、結局どのツールを選び、どう繋ぐか」を1記事で判断できる状態になることです。
そのために、次の順序で進めます。まず4ツールの違いを整理し(ここが最重要)、次に各ツールの正体を説明し、最後にClaude Codeへ接続して費用とセキュリティを検証します。
ローカルLLMツールは2026年時点で乱立しており、「とりあえず有名なものを入れたが、自分の用途に合っていなかった」という遠回りが起きやすい領域です。最初に判断軸を持つことが、いちばんの時短になります。
【混乱整理】Ollama / LM Studio / Lemonade / Foundry Local — どれを使うべきか
最初に結論を表で示します。 ローカルLLMツールは「どのハードウェアで動かすか」で選ぶのが鉄則です。
| ツール | 主戦場ハード | 形態 | 強み | こういう人向け |
|---|---|---|---|---|
| Ollama | Apple Silicon / NVIDIA | CLI | 最速セットアップ・巨大エコシステム | Mac/汎用の既定解。開発者の第一候補 |
| LM Studio | クロスプラットフォーム | GUIアプリ | 視覚的にモデルを探索・DL・実行 | CLIが苦手な初心者・GUI派 |
| Lemonade | AMD Ryzen AI / Radeon | 常駐サービス | NPU/iGPU活用で電力効率が高い | AMD機オーナー・省電力で常駐させたい層 |
| Foundry Local | Windows / macOS / Linux(クロスプラットフォーム) | SDK | 自作アプリにローカルAIを同梱できる | OSを問わず社内アプリにローカルAIを組み込む企業開発者 |
選び方の鉄則は、たった4行です。
- Mac → Ollama
- AMD Ryzen AI / Radeon → Lemonade(NPUが効く)
- GUIで気軽に試したい → LM Studio
- 社内アプリ(Windows/macOS/Linux)にローカルAIを組み込みたい → Foundry Local
ここで誤解しやすいのが Lemonade です。海外では「Nvidia前提のAIガイドを過去のものにした」と評されるほど注目されていますが、その強みはAMD Ryzen AIのNPUを使える点にあります。Apple Silicon Macでも動作はしますが、Mac上では成熟したOllamaのほうが扱いやすく、あえてLemonadeを選ぶ理由は薄いというのが正直なところです。
つまり、Macユーザーの本記事の実用的な主役は Ollamaであり、Lemonade・Foundry Localは「自分のハードが変わったときの選択肢」として押さえておく、という整理になります。
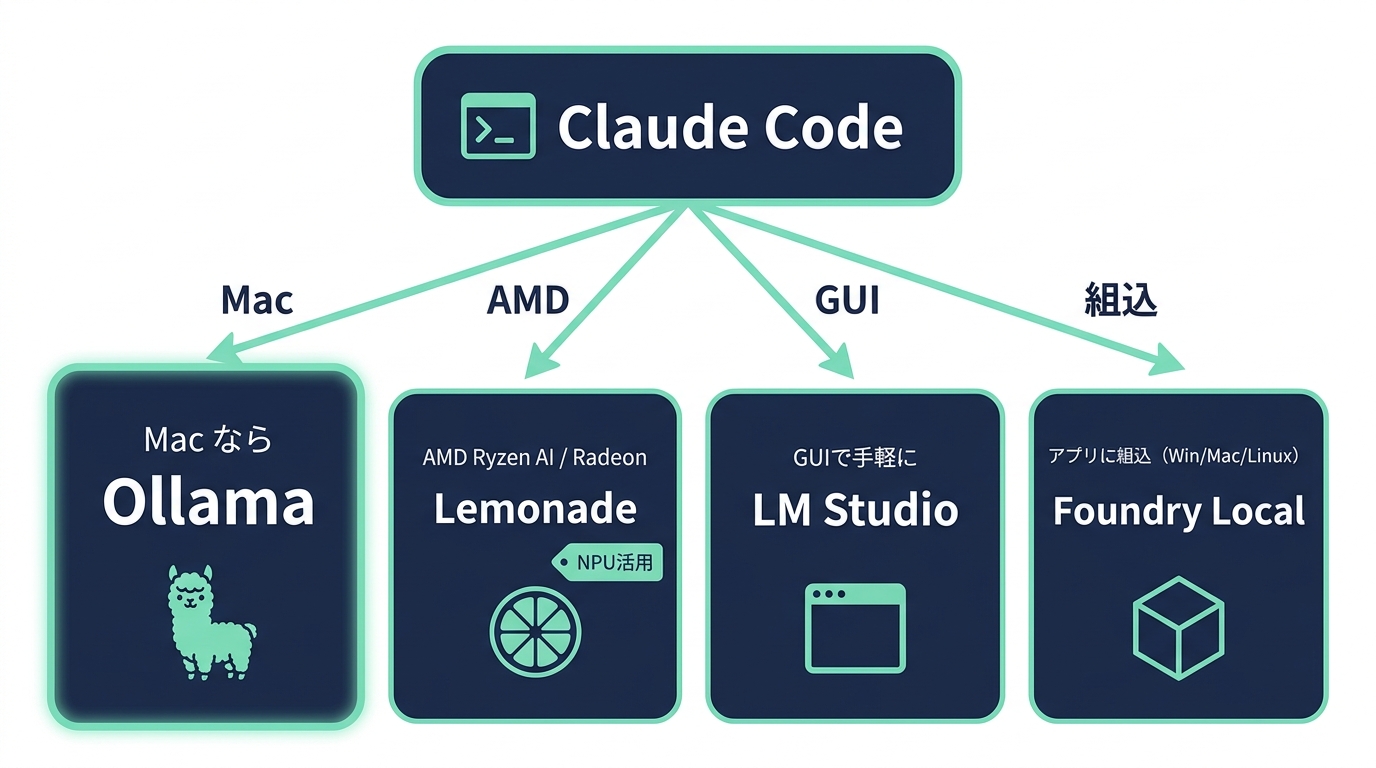
図: 使うハードで選ぶ — 4ツールの判断ツリー
Ollama — Macでローカルにする第一候補
MacでローカルLLMを動かすなら、まずOllamaで始めるのが最短です。 モデル管理・推論・REST APIを単一のCLIにまとめており、インストール後に ollama pull でモデル名を指定するだけで使えます。GPUアクセラレーション、量子化の選択、コンテキスト長の設定を、すべて妥当なデフォルトで肩代わりしてくれます。
Apple Siliconでの性能が良く、統合エコシステムが豊富なため、Claude Codeのようなツールとの接続事例も最も多く見つかります。「迷ったらOllama」で問題が起きにくいのが、第一候補に挙げる理由です。
# インストール後、コーディング向けモデルを取得して起動
ollama pull qwen3-coder:30b # 2026年の定番コーディングモデル(MoE 30B / active 3.3B)
ollama run qwen3-coder:30b
補足: 以前の定番だった
qwen2.5-coderは1世代前です。2026年5月時点の定番はqwen3-coder(MoE構造で総30B・実効3.3Bパラメータ)。メモリが厳しい16GB機では、より小さいqwen3:8b(約5.2GB)などから始めるのも手です。最新の利用可能モデルはollama listと公式モデルライブラリ(ollama.com/library)で確認できます。
LM Studio — CLIが苦手なら、まずGUIで体験する
コマンドラインに抵抗があるなら、LM Studioから入るのが挫折しにくい選択です。 macOS / Windows / Linux対応のデスクトップアプリで、モデルの検索・ダウンロード・実行をすべてGUIで完結できます。チャットUIを内蔵し、OpenAI互換のローカルAPIサーバーも立てられるため、「まず手元で動かして感触を掴む」用途に向いています。
開発ワークフローに本格的に組み込む段階ではOllamaに乗り換える人が多いですが、最初の一歩としての分かりやすさではLM Studioが優れています。
Lemonade — AMD Ryzen AI/NPUが本領のローカルAIサーバー
LemonadeはAMDがスポンサーするオープンソースのローカルAIサーバーで、AMD機なら有力な選択肢です。 10MB未満の軽量バイナリ(処理の本体はPythonベースで、推論など性能が要る部分をC++/Rustで実装)として常駐し、LLMだけでなく画像生成・音声認識・音声合成までローカルで動かせます。OpenAI互換に加えてAnthropic互換のAPIを http://localhost:13305/v1 で提供する点が、Claude Code連携で効いてきます。
最大の特徴は、AMD Ryzen AIのXDNA2 NPUに対応していることです。NPUにオフロードすることで、ツールを多用するエージェント処理で電力あたりの処理効率(tokens/watt)がCPU推論より改善するとされています(ただしAMD公式資料は「電力効率の最適化」と定性的に述べるにとどまり、具体的な倍率は公表していません)。バックエンドは用途に応じて使い分けられます。
llamacpp: GGUFモデル(Vulkan / ROCm / CUDA / CPU / Metal)flm/ryzenai-llm: NPU(XDNA2)vllm: ROCm(実験的)
繰り返しになりますが、この強みが活きるのはAMD環境です。Mac(Metal)でも llamacpp バックエンドで動きますが、その用途ならOllamaで十分というのが本記事の立場です。AMD Ryzen AIノートやRadeonを持っている、あるいはこれから組む予定がある場合に、Lemonadeは「自分のハードを最大限使える選択肢」として候補に入ります。
Foundry Local — 「ローカルAI同梱アプリ」を作るとき(Windows/macOS/Linux対応)
自作アプリにローカルAIを同梱して配布したいアプリ開発者には、Foundry Localが向いています。 これはMicrosoftが提供するローカルAIソリューションで、SDK(C# / JavaScript / Rust / Python)を通じてQwenシリーズやWhisperシリーズなどを自作アプリに組み込み、ローカル実行できます。Windowsだけでなく macOS(Apple Silicon)・Linux にも対応するクロスプラットフォーム製品で、MacではApple SiliconのGPU加速も効きます。単体でClaude Codeを動かす用途というより、プロダクトにローカルAIを埋め込む場面でのツールです。
「社内に配るツールにAIを載せたいが、クラウド送信は規定で不可」といった企業内のニーズに、OSを問わず合致します。
Claude Code をローカルモデルに接続する — 2026年はワンコマンド
ここが本題で、しかも2026年に一番ラクになった部分です。 少し前まではClaude Code側に環境変数を手で設定する必要がありましたが、いまは ollama launch claude の1コマンドで、環境変数も設定ファイルも触らずにClaude Codeをローカルモデルで起動できます。
方法1(推奨): ollama launch claude — Mac×Ollamaの最短ルート
Ollama v0.15 以降、コーディングエージェントを一発で起動する ollama launch が用意されました。実際に手元の Ollama 0.24 で確認すると、claude のほかに codex / opencode / copilot / droid / cline / vscode など主要エージェントが並びます。
# プロジェクトのディレクトリで実行するだけ
ollama launch claude
# 使うモデルを指定する場合(ローカルモデル)
ollama launch claude --model qwen3-coder:30b
# Codex も同じ体系で起動できる
ollama launch codex
これだけでローカルモデルに繋がった Claude Code が立ち上がります。環境変数の設定は不要です。
方法2(手動・フォールバック): 環境変数で繋ぐ
ollama launch が使えない環境や、挙動を自分で把握したい場合は、Ollamaが提供する Anthropic Messages API 互換(v0.14 以降)に環境変数で向ける方法もあります。
export ANTHROPIC_BASE_URL=http://localhost:11434 # OllamaのAnthropic互換エンドポイント
export ANTHROPIC_AUTH_TOKEN=ollama # ダミートークン
export ANTHROPIC_API_KEY="" # 空でよい
claude --model qwen3-coder:30b
- エンドポイント:
http://localhost:11434(Codex等のOpenAI互換はhttp://localhost:11434/v1) - クラウドの大型モデルを使いたい場合は
ollama signin後に--model glm-5:cloudのように:cloud付きで指定できます(「ローカルか課金APIか」の中間の選択肢)
参考: Lemonade のネイティブ連携(AMD機向け)
AMD機でLemonadeを使う場合も、同じ発想のワンコマンドがあります。
lemonade list # 利用可能モデルを確認
lemonade pull <model>
lemonade launch claude # Claude Code をローカルモデルで起動
- ローカルサーバー:
http://localhost:13305/v1(クライアントによっては/api/v1) - APIキー: 本来不要だが、OpenAI互換クライアントには placeholder として
lemonadeを指定
つまり Ollama も Lemonade も「
launch一発でClaude Codeに繋がる」時代です。Macならollama launch claudeが最短、AMDならlemonade launch claudeが本命、という対応になります。
コーディングに使えるローカルモデルの選び方
モデルは「ハードの余力」と「コード品質」のトレードオフで選びます。 大きいモデルほど賢い傾向はありますが、メモリに乗らなければ動かず、乗っても遅ければ実用になりません。2026年5月時点の具体的な選び方は次の通りです。
| 用途・ハード | 推奨モデル(2026年5月時点) | 目安サイズ | ひとこと |
|---|---|---|---|
| コーディング本命(24GB以上) | qwen3-coder:30b(MoE 30B / active 3.3B) | 約19GB(Q4) | 旧 qwen2.5-coder の後継。エージェント用途に最適化 |
| 16GB機で現実的に | qwen3:8b(汎用) / Qwen3-Coder 7-8B級 | 約5GB | コンテキストを絞れば16GBでも動く |
| とにかく軽く動かす | Gemma系の軽量版(例: gemma4:e2b) | 約7GB | まず「動くこと」を確認する段階向け |
| クラウド大型を使う | glm-5:cloud 等(ollama signin 後) | — | ローカルに収まらない規模を従量で |
ここで注意したいのが MoE(Mixture of Experts)構造の読み方です。qwen3-coder:30b は「実効3.3B」と表記されますが、これは1トークンあたりの計算量が小さいという意味で、必要メモリは別物です。全30B分の重みはメモリに展開されるため、フットプリントは総パラメータ規模で効きます(後述の実測でも16GB機には収まらず激遅でした)。「実効3.3Bだから16GBでも軽い」という誤読は禁物で、メモリは総サイズで見積もってください。
補足: かつての定番
qwen2.5-coderは1世代前です。コード特化の最新は Qwen3-Coder 系のほか、GLM-4.7-flash / GLM-5、gpt-oss なども選択肢に入ります。更新が速い領域なので、最新はollama listと公式モデルライブラリ(ollama.com/library)で確認してください。
実機ベンチマーク: ローカル(M5 16GB)で測ってみる
結論を先に書きます。 M5 MacBook Pro(16GB)でOllamaから5BクラスのモデルをQ4で動かすと、warm状態で約66トークン/秒、cold起動から最初の応答までは約6秒でした。短いコーディング相談を回す用途なら、体感としては「待たされる感じはない」レベルです。
検証環境とコマンド:
| 項目 | 内容 |
|---|---|
| ハード | MacBook Pro M5(10コア: 4 perf + 6 eff)、16GB RAM、macOS 26.x |
| ランナー | Ollama 0.24.0 |
| モデル | gemma4:e2b(Gemma 4 系、約5.1B パラメータ、Q4_K_M 量子化、ディスク 7.2GB) |
| プロンプト | “Write a Python function that computes the n-th Fibonacci number iteratively. Include a brief docstring.”(出力上限 256 トークン) |
| 計測 | POST /api/generate のレスポンス内 total_duration 等を使用、3トライアル |
実測結果:
| トライアル | 状態 | 総時間 | モデルロード | 生成トークン数 | 生成速度 |
|---|---|---|---|---|---|
| 1 | cold | 10.6 秒 | 6.0 秒 | 256 | 64.4 tok/s |
| 2 | warm | 4.2 秒 | 0.2 秒 | 256 | 65.8 tok/s |
| 3 | warm | 4.1 秒 | 0.2 秒 | 256 | 66.8 tok/s |
読み解き方のポイント:
- cold/warmの差はモデルロード。初回だけ約6秒の追加待ち時間が発生し、その後は ~4 秒で 256 トークン分の生成を終えます。
- 生成速度はトライアル間で安定(64〜67 tok/s)。M5の Apple Silicon GPU/Neural Engine がしっかり効いていることが分かります。
- プロンプト評価はキャッシュが効く。同一プロンプト2回目以降は 0.02 秒で完了するため、繰り返し系のワークフローでは体感がさらに速くなります。
現行コーディングモデル qwen3-coder:30b を16GBで動かすと?
では2026年定番の qwen3-coder:30b(MoE、ディスク18GB)を同じM5/16GB機で動かすとどうなるか。結論は「16GBには大きすぎて実用にならない」でした。
ollama ps で確認すると、このモデルはメモリ上で 約22GB のフットプリントを占め、16GBの物理メモリに収まりきらず CPU 47% / GPU 53% に分割されていました(本来GPUに載せたい処理がCPUへ溢れている状態)。
実測の生成速度は わずか 0.20 tok/s(モデル常駐済みの状態で、128トークンの生成に637秒)。同じ16GB機の gemma4:e2b が 66 tok/s だったので、ざっと330倍遅い計算です。1回の応答に9〜20分かかり、対話用途にはまったく耐えませんでした。
| モデル(同じM5/16GB機) | 生成速度 | 256トークンの体感 |
|---|---|---|
gemma4:e2b(5.1B, 7.2GB・収まる) | 66 tok/s | 約4秒 |
qwen3-coder:30b(MoE, 18GB・溢れる) | 0.20 tok/s | 約20分 |
- MoEで「実効3.3B」とはいえ、全30B分の重みはメモリに展開されるため、必要メモリは総パラメータ規模で効いてくる
- つまり
qwen3-coder:30bは 24〜32GB以上のマシン向け。16GB機では後述の8Bクラスに留めるのが現実的
⚠️ モデル選びの注意:
gemma4:e2bは内部に「thinking」を持つ推論モデル系で、出力トークン数が小さいと思考途中で打ち切られて返答テキストが空になることがあります(実測でもdone_reason:"length"でresponse:""になるケースを観測)。コーディング用途ではqwen3-coder系などコード特化モデルのほうが、同じトークン予算で実用的な答えが返ってきます(次項で同じ16GB機での実測を示します)。
Claude Pro/Max との比較について: Claude側の正確な tokens/sec はモデル・経路・時間帯で揺れるため、ここでは ayumu の Mac で取れたローカル数値の事実だけを提示します。読者が自分の環境で比較できるよう、同じ手順(Ollama + /api/generate の total_duration/eval_count)を上に書きました。同じプロンプトを Claude Code 経由で計測し、自分のワークロードに照らして判断するのが現実的です。
セキュリティ検証: 本当にクラウドに送られないか — そして「localhost専用」の落とし穴
結論を先に書きます。 Ollamaに推論を投げている間、外部サーバーへの通信は発生していませんでした(同一マシン内の127.0.0.1接続のみ)。ただしOllamaの API ポート 11434 はデフォルトで全ネットワーク・インターフェースに対して待ち受けています。「ローカル動作だから安全」と思い込まず、明示的な縛りを入れるのが安全な運用です。
実機で取った lsof 結果(M5 + Ollama 0.24):
COMMAND PID USER FD TYPE NODE NAME
ollama 2212 ayumu 3u IPv6 TCP *:11434 (LISTEN) ← APIサーバー: 全インタフェース待受 ⚠️
ollama 23564 ayumu 4u IPv4 TCP 127.0.0.1:59737 (LISTEN) ← モデル実行子プロセス: localhost のみ
ollama 2212 ayumu 11u IPv4 TCP 127.0.0.1:59775->127.0.0.1:59737 (ESTABLISHED)
ollama 23564 ayumu 6u IPv4 TCP 127.0.0.1:59737->127.0.0.1:59775 (ESTABLISHED)
読み解き方:
- モデル本体(PID 23564)は 127.0.0.1 のみで待ち受け、外部に通信していない(推論中の通信は親プロセスとの localhost ループのみ)
- APIサーバー(PID 2212)の
*:11434は IPv6 ワイルドカード = 同じネットワークからアクセス可能な状態。Macのファイアウォール設定次第ではあるが、デフォルトの状態に油断は禁物 - 推論中に外部 IP への接続は一切観測されず、「クラウドに送られない」自体は事実として確認できた
機密案件で安心して使うための明示設定:
# Ollama を起動するシェル / launchd で環境変数を設定
export OLLAMA_HOST=127.0.0.1 # localhost のみで待受
export OLLAMA_ORIGINS= # 不要なオリジンを弾く
補足:
*:11434の状態でも、macOS の「システム設定 → ネットワーク → ファイアウォール」が有効なら外部からの新規接続はブロックされます。とはいえ「アプリ単位でファイアウォール許可」が記憶ベースで増えていく実運用では、明示的に127.0.0.1に縛るほうが事故が起きません。さらに踏み込んでtcpdump/pktapで全パケット監査するのは sudo が必要なため、機密用途では別途実施してください。
コスト試算(月額$0 vs $100)と必要スペック
費用面の結論はシンプルで、ローカル運用はAPI/サブスク費用が月額$0になります。 Claude CodeをPro/Maxのサブスクや従量APIで使う場合との差分が、そのまま削減額です。
| 項目 | ローカル運用 | Claude Pro/Max |
|---|---|---|
| 月額費用 | $0(電気代のみ) | 月額サブスク or API従量 |
| 初期コスト | 対応ハード(既に所有なら$0) | なし |
| 速度・品質 | ハード依存(次の表参照) | 安定して高い |
実測ベースの必要スペック目安(Apple Silicon Mac で Ollama を回す前提):
| ハード | 動かせるモデル目安 | 体感 | 出典 |
|---|---|---|---|
| 8GB機(M1/M2 Air 等) | 3BクラスのQ4 or 2BクラスのQ8 | 動くが context を絞らないと swap が走りやすい | 一般的な経験則 |
| M5 / 16GB(本記事の検証機) | 5〜8BクラスのQ4(gemma4:e2b/qwen3:8b 等、ディスク5-8GB) | 約66 tok/s、warm 4秒で256トークン生成。qwen3-coder:30b は不可(22GB占有・CPU47%溢れ・0.20 tok/s) | 本記事 実測 |
| 24〜32GB以上 | qwen3-coder:30b(MoE) など本格コーディングモデル | 30B級が実用域に。コード品質が一段上がる | 本記事 実測(16GBでの不足から逆算) |
ただし「タダより速い・賢い」わけではありません。ローカルは自分のハードの性能が上限で、Claude Pro/Maxの安定した品質には及ばない場面もあります。とくに2026年の定番 qwen3-coder:30b を快適に使うなら 24GB 以上が目安——16GB機では8Bクラスに留め、本格的なコーディングモデルが必要になったらメモリを増やす、という判断が現実的です。
やりがちなアンチパターン3選
ローカルLLMでClaude Codeを動かすとき、遠回りしやすい失敗を3つ挙げます。
❌ MacでわざわざLemonadeを選ぶ — Lemonadeの強みはAMD NPU。Macでは成熟したOllamaのほうが素直に動きます。ハードに合ったツールを選びましょう。
❌ NPU非対応機でNPUの恩恵を期待する — Lemonadeの電力効率の話はRyzen AIのNPUが前提です。対応していないハードでは、その利点は得られません。
❌ 手持ちのメモリに対してモデルが大きすぎる — 「賢いほうがいい」と最大級のモデルを選ぶと、メモリに乗らない・遅すぎて実用にならない、という事故が起きます。本記事でも16GB機に qwen3-coder:30b(18GB)を載せたら22GB占有・CPU47%溢れ・0.20 tok/s(収まる5Bモデルの約330分の1)でした。MoEの「実効3.3B」に釣られず、全パラメータ規模でメモリを見積もること。まず小さく動かし、余力を見て上げるのが安全です。
まとめ
ローカルLLMでClaude Codeを動かす最大のハードルは、ツール選びの段階の混乱です。要点を再掲します。
- Mac → Ollama が実用的な第一候補
- AMD Ryzen AI / Radeon → Lemonade(NPUが活きる)
- GUIで気軽に → LM Studio、社内アプリ(OS問わず)に組み込み → Foundry Local
- ローカル運用の価値は「API費用ゼロ」と「コードを外部送信しない」の2点。後者は通信ログで実証してこそ意味がある
まずは自分のハードに合ったツールを1つ選び、ollama launch claude でClaude Codeをローカルモデルに繋いでみてください。次の一歩として、本記事の実機ベンチマークとセキュリティ検証の数値を、お使いの環境で実際に取ってみることをおすすめします。
コメント