
近年、ChatGPTに代表される大規模言語モデル(LLM)が大きな注目を集めています。
しかし、クラウドAPIを利用するには料金がかかります。
API利用することで、マシンスペックに依存せずにAIの性能を最大限活かせる魅力は当然ありますが、個人的にはせっかくAI用にGPU(RTX3060 12GB)を買ったので有効活用したいと思っていました。
そこで、LLMをローカル環境で手軽に体験できるオープンソースツール「Ollama」の魅力に迫ります。
インストール方法
Ollamaは、MacやLinux、Windowsなど主要なOSに対応しており、簡単にインストールできます。
今回は3月にプレビュー版としてリリースされたWindowsでのインストール方法について紹介します。

Windowsのインストーラーをダウンロード、実行します。
インストールボタンをクリックして、しばらく待ったら完了です。
コマンドプロンプトまたはPowerShellを起動します。
以下のコマンドを実行して、バージョンが出力されればOKです。
ollama -v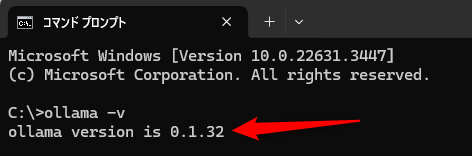
多様なモデルをサポート
Ollamaは、Llama、Gemma、Mistral、Dolphin Phiなど、多様なオープンソースのLLMをサポートしています。
現在公開されているモデルは以下のリンクからご確認してください。
モデルサイズもさまざまありますので、マシンスペックに合わせて利用することができます。
ハードウェアアクセラレーションにも対応
GPUを搭載したマシンでは、NVIDIAのGPUアクセラレーションを利用してパフォーマンスを引き出せます。
CPU命令セットのIntel AVX/AVX2にも対応しており、幅広いハードウェア環境で効率的に動作します。
プレビュー版ですが、Windowsで簡単にセットアップできるようになりました。
https://atmarkit.itmedia.co.jp/ait/articles/2403/12/news068.html
動作確認
今回はLlama3がリリースされたばかりなので、早速使ってみたいと思います。
ollama run llama3コマンドを実行すると、最新のllama3を取得します。
約4.7GBあるのでダウンロードには少し時間がかかります。

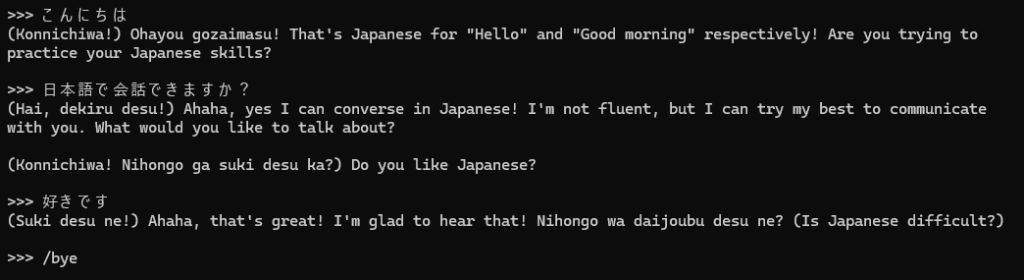
セットアップが完了したら、そのままコマンドプロンプト上で会話ができます。
Llama3は日本語に少し弱いと言われていますが、日本語で喋ってみたところ、そのようです。
まとめ
Ollamaを使えば、大規模言語モデルの力を、誰でも手軽にローカル環境で体験できます。
シンプルなインターフェース、多様なモデルのサポート、ハードウェアアクセラレーション、柔軟な開発オプションが魅力です。AIの民主化が進む中、Ollamaのようなオープンソースツールの重要性は今後ますます高まっていくでしょう。
他システムDifyと連携したいので、Dockerを使った環境構築方法も紹介したいと思います。
コメント