
はじめに
前回記事では M2 MacBook Air 8GB で
Gemma 4 と Whisper の日本語音声認識を比較しました。
そのとき Gemma 4 E4B は [METAL] Command buffer execution failed: Caused GPU Timeout Error
で動かず、「16GB 機なら動くかも」とだけ書いて締めくくっていました。
その後ハードウェアを M5 MacBook Pro 16GB に入れ替えたので、
同じ4モデル・同じ10サンプルで再ベンチマークしました。
結論から言うと:
- Gemma 4 E4B が動いた(M2 8GB では時間切れだった)
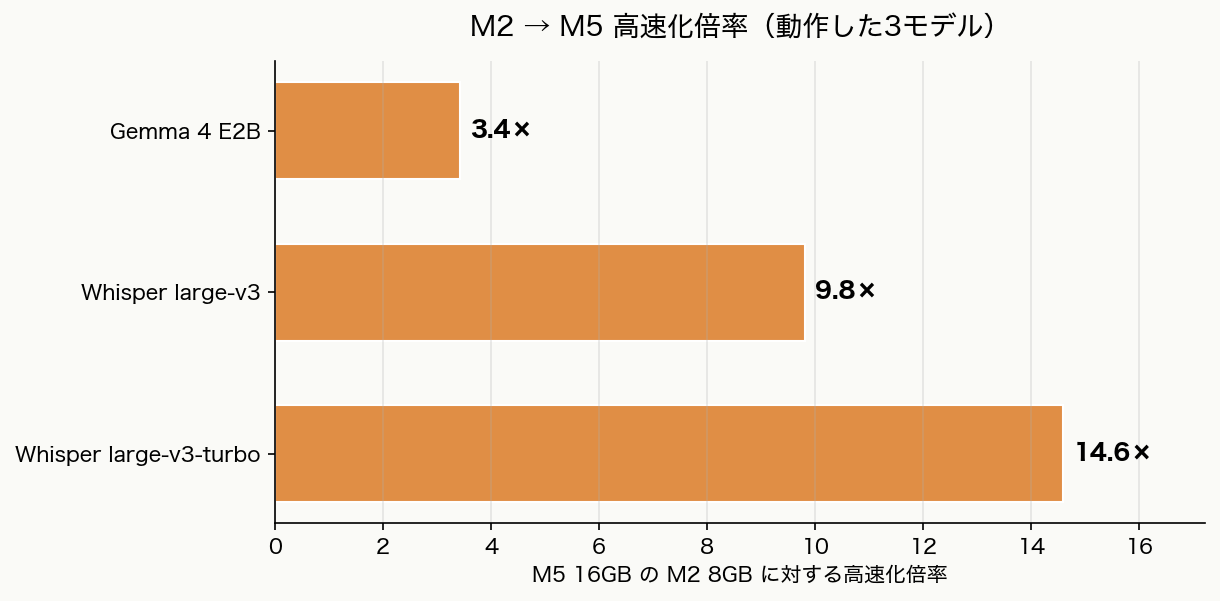
- 動作した3モデルで 3〜15 倍の高速化
- Whisper large-v3-turbo は 1秒未満(0.61s/サンプル)に到達
数字と一緒に、検証中に踏んだ macOS 側の落とし穴も共有します。
計測条件(前回と同じ)
- 評価データ: macOS の
sayコマンド (Kyoko 音声) で合成した日本語10サンプル
(短文5本・中文3本・長文2本、合計約 70 秒) - 評価指標: CER(cleaned: Gemma の
GenerationResultrepr からtext=を抽出後) - スクリプト: hrtaym1114-github/gemma4-whisper-bench
のbenchmark.py
uv sync
uv run python prepare_data.py # データ生成
uv run python benchmark.py # 全モデル走らせる
uv run python fix_gemma_results.py # Gemma の出力をクリーンハードウェア比較
| 項目 | 前回 | 今回 |
|---|---|---|
| 機種 | MacBook Air | MacBook Pro |
| チップ | Apple M2 | Apple M5 |
| RAM (Unified) | 8GB | 16GB |
| macOS | 26.x | 26.3 |
| Python | 3.13 | 3.11 |
| 測定日 | 2026-04-18 | 2026-04-29 |
結果サマリー
平均推論時間(秒/サンプル)
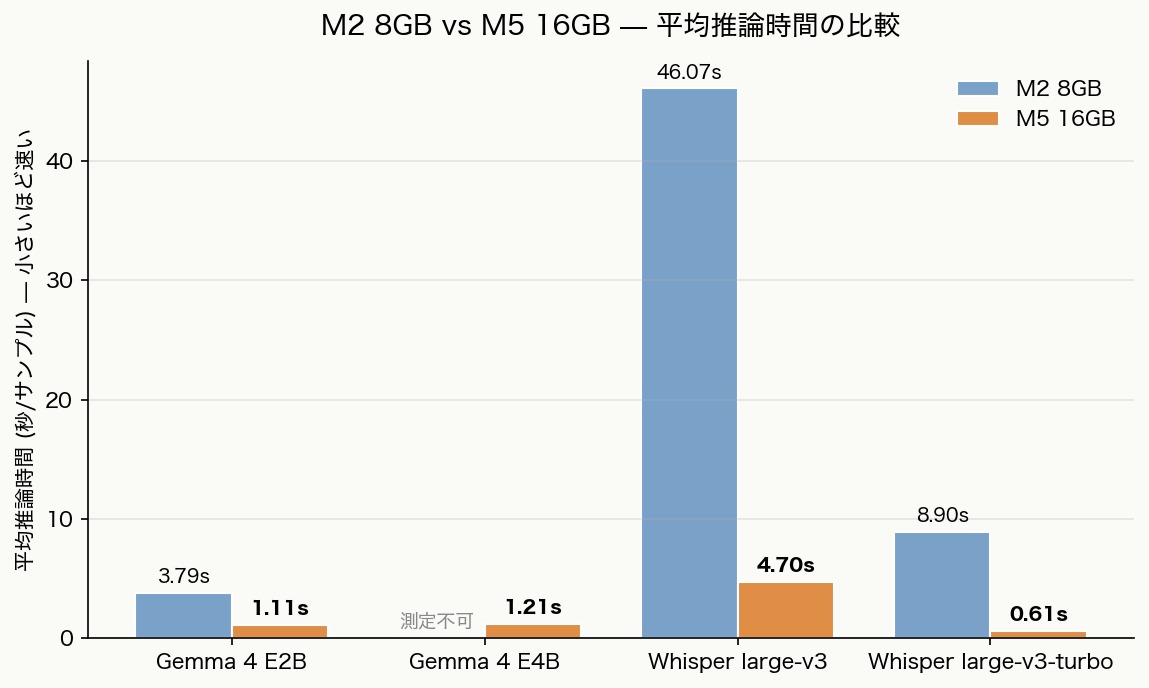
| モデル | M2 8GB | M5 16GB | 高速化 |
|---|---|---|---|
| Gemma 4 E2B | 3.79 | 1.11 | 3.4× |
| Gemma 4 E4B | 測定不可 | 1.21 | 動作するように |
| Whisper large-v3 | 46.07 | 4.70 | 9.8× |
| Whisper large-v3-turbo | 8.90 | 0.61 | 14.6× |
CER(cleaned)
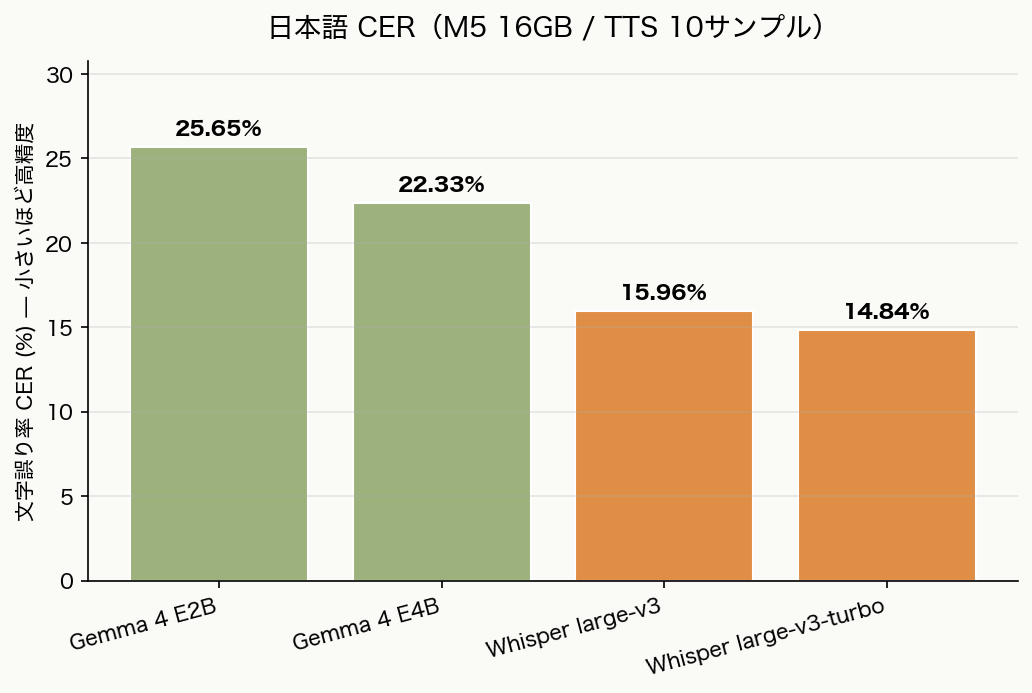
| モデル | M2 8GB | M5 16GB |
|---|---|---|
| Gemma 4 E2B | 25.65% | 25.65% |
| Gemma 4 E4B | — | 22.33% |
| Whisper large-v3 | 15.96% | 15.96% |
| Whisper large-v3-turbo | 14.84% | 14.84% |
CER 自体は当然変わりません(モデルの重みは同じ)。
精度面の収穫は「E4B の数字が初めて取れた」点です。
E4B は E2B より約 3 ポイント低 CER で、Whisper には届きませんが、
小型 LLM 系では悪くないラインに乗ってきています。
トピック1: Gemma 4 E4B が動くようになった
E4B は前回 M2 8GB で Caused GPU Timeout Error でクラッシュ。
Apple Unified Memory なので、推論中に他プロセスと物理 RAM を取り合った結果、
Metal コマンドバッファがタイムアウトしていた様子。
M5 16GB では推論中の peak memory(mlx-vlm 自身の報告値)が
サンプルにより 5.4〜6.0 GB で推移しました。
8GB 機ではこのワーキングセットに OS や他アプリの常駐メモリが加わると物理 RAM 不足になり、
swap/compress が走った瞬間に Metal タイムアウトに到達する、
という挙動だったと推測しています(推測なので断定はしません)。
実用観点では:
- E4B を本気で使うなら 16GB 以上ほぼ必須
- E2B と E4B のレイテンシ差はほぼ無い(1.11s vs 1.21s)
- 一方 CER は E4B のほうが 3 ポイント以上良い → 16GB 機なら E4B 一択
トピック2: Whisper large-v3-turbo が秒速以下に
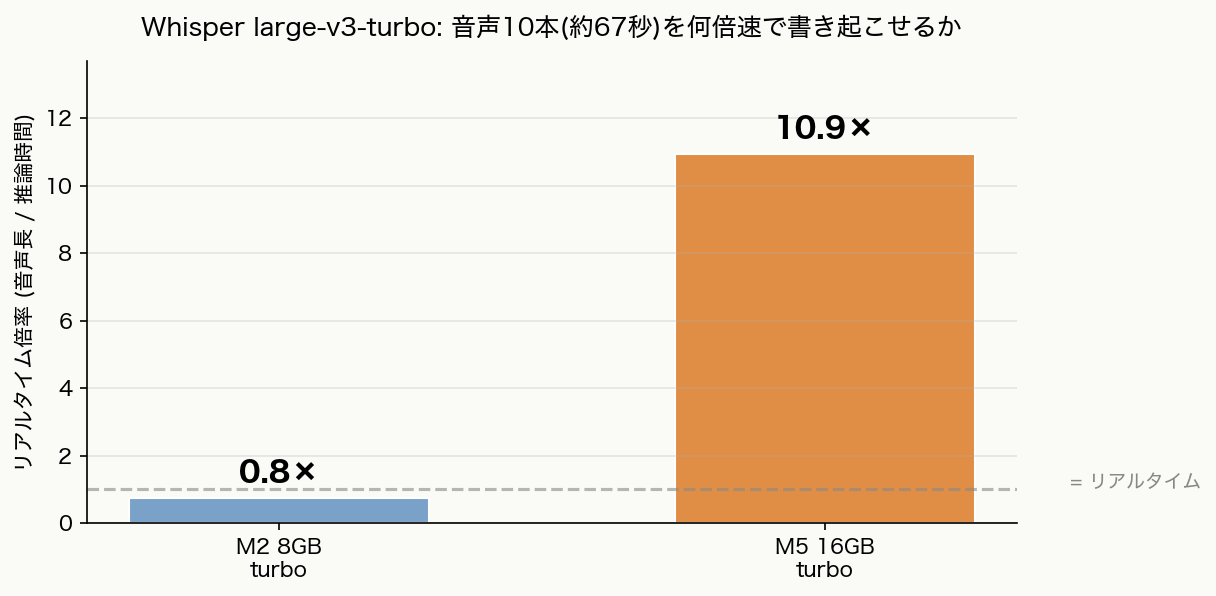
| 指標 | M2 turbo | M5 turbo |
|---|---|---|
| 平均推論時間 / サンプル | 8.90s | 0.61s |
| 10サンプル合計 wall-clock | — | 6.12s |
| 10サンプルの音声合計長 | 約 67s | 約 67s |
| 速度比(音声長 / 推論時間) | 約 0.75× | 約 11× |
M5 では入力音声長の 10 倍以上のスピード で書き起こしが走るので、
ストリーミング(マイク入力)処理にも余裕で間に合います。
CER 14.84% は前回からの最強モデルそのままなので、
M5 16GB なら Whisper large-v3-turbo を素直に使うのが現実解 という結論は変わらず、
むしろ強化された形です。
トピック3: 踏んだ macOS 側の落とし穴
M5 への移行で uv sync 済みの venv をそのまま持ち込んだら、
初回 import に 30 分以上かかる現象に遭遇しました。
mlx_vlm が transformers + torch + sympy + sklearn + pandas など
重量級ライブラリを連鎖的に読み込むため、
個々の小ファイルアクセスが macOS 側でボトルネックになっている疑いが濃厚です。
原因切り分け中に見つけたものを共有します。
1. com.apple.provenance 拡張属性
macOS Sequoia 以降、ダウンロードしたファイルにはcom.apple.provenance という拡張属性が付きます。
新規環境で初めてアクセスする際に検証が走り、
venv 配下に約 3300 個の属性が付いていました。
# 確認
xattr -r .venv | head
# 削除(venv 配下のみ、ユーザーデータには触らない)
xattr -dr com.apple.provenance .venv
xattr -dr com.apple.provenance ~/.cache/huggingface削除単独での効果は他の対処と切り分けできていませんが、
新規 Mac で venv を引き継いだときの定番ケアとしてやっておく価値はあります。
2. tracemalloc.start() の位置に注意
元の benchmark.py は tracemalloc.start() を import mlx_vlm の 前 で呼んでいました。
import 中のアロケーションを全部トレースしてしまうので、
重量級ライブラリの初回ロードでは overhead が大きくなりがちです。
ローカルで runner 内に閉じ込めるよう修正して、
import が終わった後に tracemalloc.start() するようにしました
(修正は本リポジトリの benchmark.py に反映済み)。
3. HuggingFace Hub への到達不可で [Errno 60] Operation timed out
mlx_vlm.load(model_id) は内部で AutoProcessor / AutoConfig を
ローカルキャッシュから読むのですが、検証のために Hub に問い合わせます。
ネットワークが不調だと 20分超ハングしてからタイムアウト。
# キャッシュだけ使う
HF_HUB_OFFLINE=1 TRANSFORMERS_OFFLINE=1 uv run python benchmark.pyこれで Hub アクセスを完全に切れます。CIで動かす場合も推奨。
今回 Gemma 系を完走させられた決め手はこのフラグでした。
推奨マトリクス(更新版)

| 用途 | 8GB Mac | 16GB Mac |
|---|---|---|
| 一般的な書き起こし | Whisper large-v3-turbo | Whisper large-v3-turbo |
| 最高精度を狙う | Whisper large-v3 | Whisper large-v3 |
| 軽量・常駐したい | Gemma 4 E2B | Gemma 4 E4B |
| 文脈考慮が欲しい | Gemma 4 E2B(CER 注意) | Gemma 4 E4B |
「音声→テキスト」を正確にやるだけなら Whisper large-v3-turbo がベスト。
「音声を踏まえた対話・要約・分類」を 同じモデルで やりたいなら Gemma 4 E4B(16GB 機で)。
まとめ
- M2 8GB → M5 16GB の入れ替えで、動作した3モデルが 3〜15 倍の高速化
- 前回測定不可だった Gemma 4 E4B が動作(CER 22.33%)
- Whisper large-v3-turbo は秒速以下 に到達、リアルタイム書き起こし用途に十分
- 16GB Mac なら Whisper turbo(精度重視) と Gemma 4 E4B(マルチモーダル汎用) の二択構造に
「Apple Silicon でローカル音声 AI を本気でやるなら 16GB から」が、
今回の検証で改めて確認できた線でした。
検証スクリプトと M2/M5 両方の生データは
hrtaym1114-github/gemma4-whisper-bench
の results/m2_8gb/ results/m5_16gb/ に置いてあります。
関連記事:
– 前回: Apple Silicon で Gemma 4 E2B は Whisper を置き換えられるか — 4モデル日本語CER実測と選定ガイド
コメント